
Wie man ein CSV-File lädt und die Daten mit pandas bereinigt.
Data Cleaning mit pandas als auvery Task
Die Analyse von Daten nimmt einen immer größeren Raum innerhalb von digitalen Geschäftsprozessen ein. Quelldaten kommen oft als CSV-Datei aus Legacy-Systemen und müssen vor der Verarbeitung aufbereitet werden. Wir schauen uns in diesem Post an, wie wir pandas innerhalb eines auvery Tasks verwenden können, um ein CSV-File zu lesen und die Daten daraus zu bereinigen.
Zudem schauen wir uns an, wie wir diesen Arbeitsschritt in einen auvery Workflow integrieren können. Dabei sehen wir, wie auvery den produktiven Betrieb dieses pandas Jobs vereinfacht.
Szenario
Wir werden den auvery Tasks mit pandas anhand eines typischen Szenarios erarbeiten. Dazu nehmen wir an, dass wir als Data Scientist für ein E-Commerce oder traditionelles Handelsunternehmen tätig sind. Unsere Aufgabe ist es, die Bestellungen des Online-Shops zu analysieren. Die Bestellungen werden einmal pro Tag als CSV-Datei aus dem etwas veralteten Warenwirtschaftssystem exportiert. Ein CSV-Export sieht zum Beispiel wie folgt aus.
OrderID,CustomerID,OrderDate,Amount,ItemCount
1001,2001,2024-01-05 14:30,59.99,3
1002,2002,2024/02/10 09:20,15.99,1
1003,2003,,22.49,
1004,2004,2024-03-15 16:45,34.99,2
1005,2005,2024-03-20,27.99,1
1006,2006,2024-04-01 12:00,,5
1007,2007,2024-04-05 18:30,49.99,2
1008,2008,2024-05-10 08:15,19.99,
1009,2009,2024/05/15 13:25,79.99,4
1010,2010,,99.99,3
In diesem Export sind drei Arten von Fehlern enthalten, die wir korrigieren wollen:
- Einige OrderDate-Einträge sind in einem inkonsistenten Format oder fehlen ganz. Zum Beispiel:
- 2024/02/10 09:20 verwendet einen anderen Datumsseparator.
- Die Spalten Amount und ItemCount haben uneinheitliche Datentypen. Einige Werte sind als Text gespeichert oder fehlen.
- Fehlende Amount und ItemCount Werte in den Zeilen 1003 und 1006.
- Die Daten enthalten fehlende Werte in den Spalten OrderDate, Amount und ItemCount, die durch die Bereinigung aufgefüllt werden müssen.
Um die Bereinigungen vorzunehmen, führen wir mit pandas die folgenden Schritte aus:
- Zeitstempel konvertieren: Die OrderDate-Spalte wird in ein einheitliches datetime-Format konvertiert.
- Datentypen ändern: Die Amount-Spalte wird in float und die ItemCount-Spalte in int umgewandelt.
- Auffüllen fehlender Werte: Fehlende Werte in OrderDate, Amount und ItemCount werden mit sinnvollen Standardwerten oder durch Mittelwertfüllung ersetzt.
Bereinigung der Daten
Jeder auvery Task, der auf Docker als Driver basiert, kann in einer beliebigen Programmiersprache implementiert werden. Das folgt daraus, dass wir Docker als Driver nutzen und somit innerhalb des Docker Images volle Freiheit haben.
Da wir pandas nutzen wollen, schreiben wir unseren Task in Python. Die Implementierung mit pandas ist recht simpel und könnte wie folgt aussehen.
# Load CSV file into pandas data frame
df = pd.read_csv(csv_file_path)
# 1. Convert timestamps
df['OrderDate'] = pd.to_datetime(df['OrderDate'], errors='coerce')
# 2. Change data types
df['Amount'] = df['Amount'].astype(float)
mean_item_count = df['ItemCount'].mean()
df['ItemCount'] = df['ItemCount'].fillna(round(mean_item_count))
df['ItemCount'] = df['ItemCount'].astype('Int64')
# 3. Fill missing values
df['OrderDate'] = df['OrderDate'].fillna(pd.Timestamp.today())
df['Amount'] = df['Amount'].fillna(df['Amount'].mean())
df['ItemCount'] = df['ItemCount'].fillna(df['ItemCount'].mean())
# Export cleaned data as JSON
df.to_json(json_file_path, orient='records', indent=4)
Mit diesen 10 Zeilen Code, haben wir bereits unsere speziellen Anforderungen umgesetzt. Dieser Code stellt als die Business-Logik unseres auvery Tasks dar.
Spezifikation eines auvery Tasks erfüllen
Damit wir diesen Code innerhalb eines auvery Tasks nutzen können und dieser Task wiederum in einen auvery Workflow verwendet werden kann, müssen wir noch einige wenige Zeilen Code ergänzen.
Der aufmerksame Leser wird bereits die Variablen csv_file_path und json_file_path bemerkt haben. Diese beiden Variablen geben die Dateipfade für unseren Input Parameter als auch unser Result an. Das csv_file_path ist unser Input Parameter und der json_file_path ist unser Result. Wir bekommen als Input die CSV-Datei und lesen sie aus. Als Result erzeugen wir ein JSON-File mit den Orders als JSON als Inhalt.
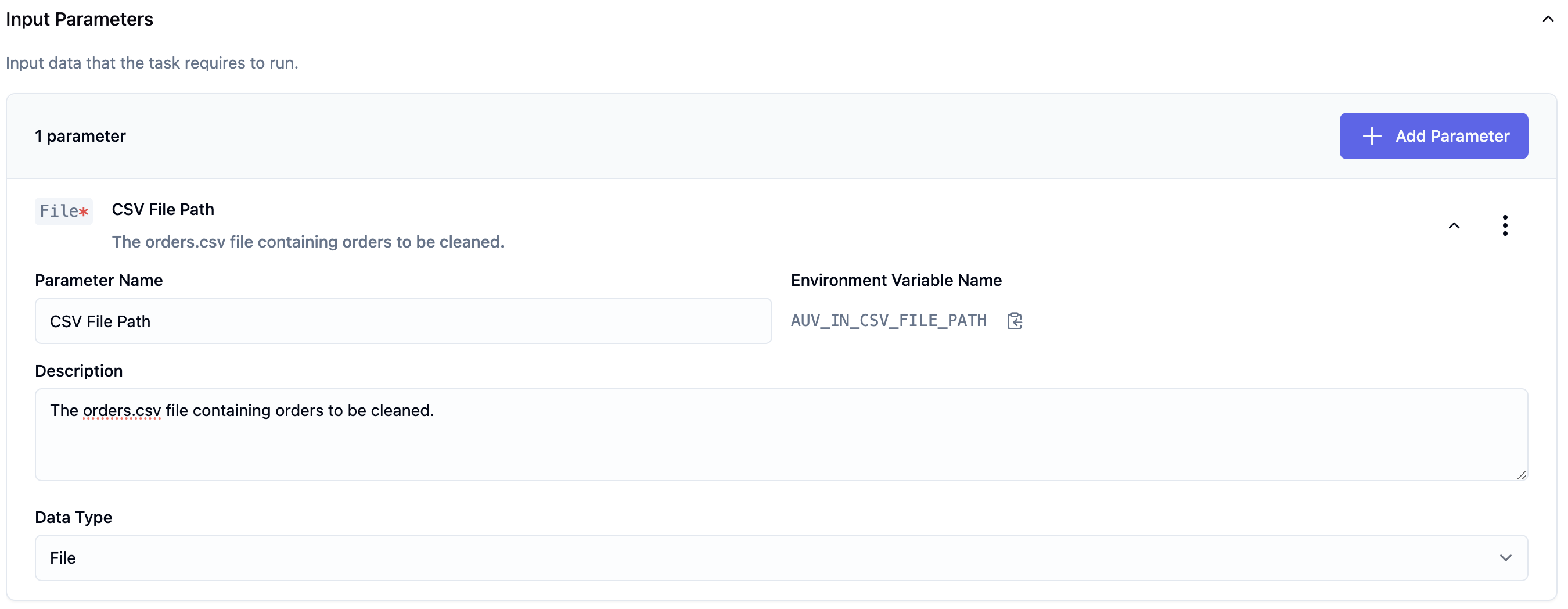
Über diese zwei Pfade bzw. Dateien stellen wir die Verbindung zu anderen Tasks innerhalb eines auvery Workflows her. Die Pfade werden uns von auvery als Umgebungsvariablen in unser Docker Image (mehr zur Erstellung später) gemapped.
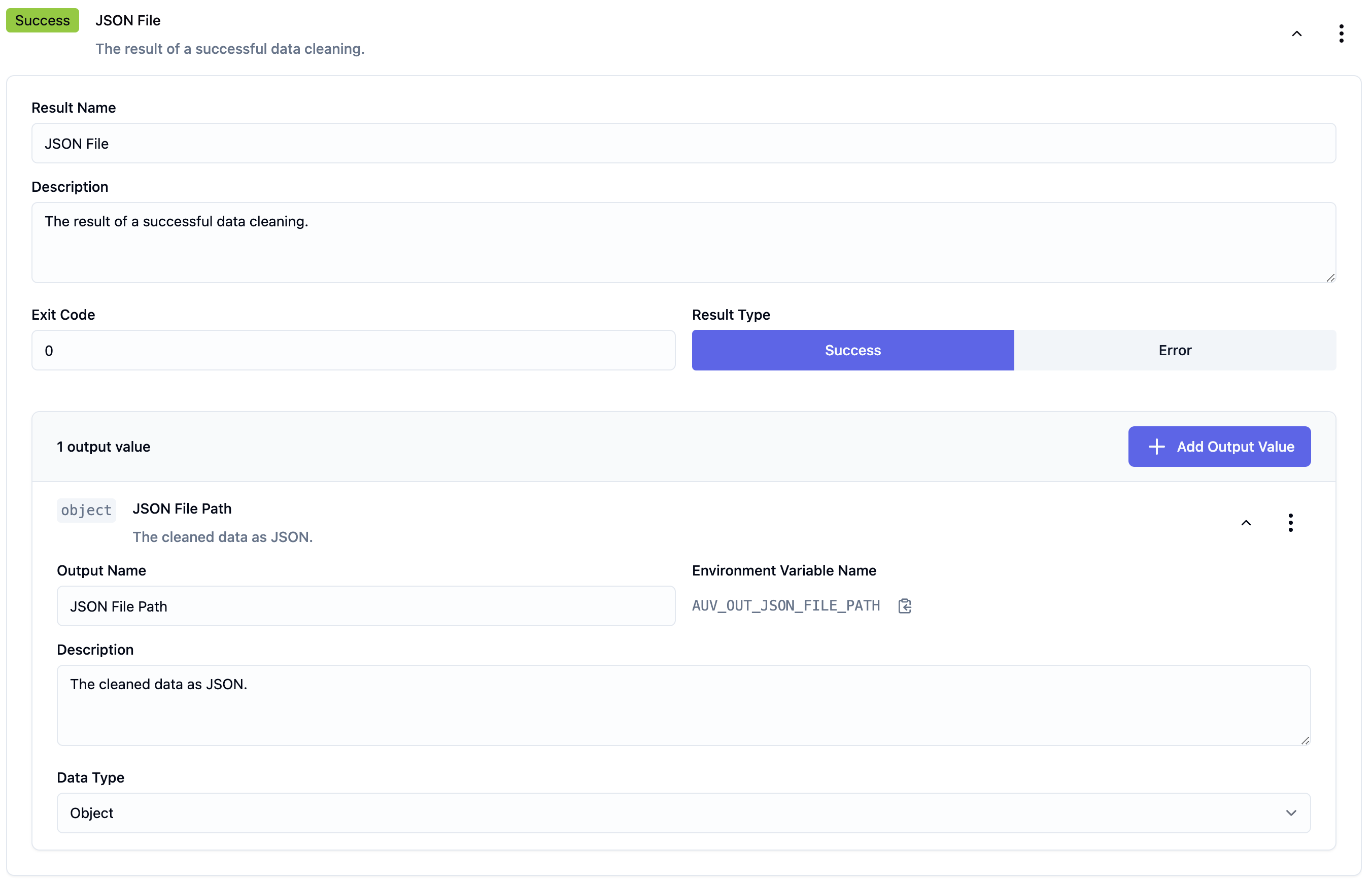
Ebenso wie Results, werden Errors in Dateien geschrieben. Wir unterscheiden hier zwei Errors - a) das Lesen der Datei schlägt fehl und b) die Bereinigung schlägt fehl.
Wir ergänzen also vier Zeilen Code.
csv_file_path = os.getenv('AUV_IN_CSV_FILE_PATH')
json_file_path = os.getenv('AUV_OUT_JSON_FILE_PATH')
error_csv_path = os.getenv('AUV_ERR_CSV_ERROR', '')
error_cleaning_path = os.getenv('AUV_ERR_CSV_ERROR', '')
Verpacken der Business-Logik in ein Docker Image
Als Letztes gilt es, unseren Code in ein Docker Image zu verpacken. Dazu benötigen wir zwei weitere Files:
- Dockerfile - Definiert, wie das Docker Image gebaut werden soll
- requirements.txt - Definiert, welche Abhängigkeiten für Python installiert werden sollen (pandas)
Das führt also für unseren Task zu folgender Projekt-Struktur.
. +-- _Dockerfile +-- _requirements.txt +-- _src | +-- clean_orders.py +-- _output (for local testing) +-- _input (for local testing)
Der Python-Code zur Bereinigung der CSV-Daten liegt in src/clean_orders.py.
Im Dockerfile legen wir ein Working Directory an, kopieren src/clean_orders.py und requirements.txt in das Directory und installieren die Abhängigkeiten (pandas) mit pip.
FROM python:3.9-slim
# Set working directory
WORKDIR /app
# Copy requirements.txt to working directory
COPY requirements.txt .
# Install Python requirements (pandas)
RUN pip install --no-cache-dir -r requirements.txt
# Copy Python script to working directory
COPY src/clean_orders.py .
# Call script when starting the container
CMD ["python", "clean_orders.py"]
Das requirements.txt enthält nur eine Zeile.
pandas
Für den vollständigen Überblick füge ich hier auch nochmal das komplette clean_orders.py an. Es ist hier noch ergänzt um die try-catch-Blöcke für die Fehlerbehandlung sowie einem Log-Statement am Ende der Bereinigung.
import os
import pandas as pd
def main():
# Input path for CSV file and result path for JSON file
csv_file_path = os.getenv('AUV_IN_CSV_FILE_PATH', '')
json_file_path = os.getenv('AUV_OUT_JSON_FILE_PATH', '')
# Error file paths
error_csv_path = os.getenv('AUV_ERR_CSV_ERROR', '')
error_cleaning_path = os.getenv('AUV_ERR_CSV_ERROR', '')
try:
# Read CSV data
df = pd.read_csv(csv_file_path)
except Exception as e:
error_message = f"Error reading CSV data: {e}"
with open(error_csv_path, 'w') as error_file:
error_file.write(error_message)
exit(1)
try:
# Do data cleaning
# Load CSV file into pandas data frame
df = pd.read_csv(csv_file_path)
# 1. Convert timestamps
df['OrderDate'] = pd.to_datetime(df['OrderDate'], errors='coerce')
# 2. Change data types
df['Amount'] = df['Amount'].astype(float)
mean_item_count = df['ItemCount'].mean()
df['ItemCount'] = df['ItemCount'].fillna(round(mean_item_count))
df['ItemCount'] = df['ItemCount'].astype('Int64')
# 3. Fill missing values
df['OrderDate'] = df['OrderDate'].fillna(pd.Timestamp.today())
df['Amount'] = df['Amount'].fillna(df['Amount'].mean())
df['ItemCount'] = df['ItemCount'].fillna(df['ItemCount'].mean())
# Export cleaned data as JSON
df.to_json(json_file_path, orient='records', indent=4)
except Exception as e:
error_message = f"Error cleaning the data: {e}"
with open(error_cleaning_path, 'w') as error_file:
error_file.write(error_message)
exit(1)
print(f"Cleaned data was successfully saved in {json_file_path}.")
exit(0)
if __name__ == "__main__":
main()
Das vollständige Projekt ist in diesem Repo hier zu finden: GitHub - auvery Task pandas data cleaning
Lokales Testen des Tasks
Der auvery Task kann nun lokal getestet werden. Dazu werden zwei Ordner im Projekt-Root angelegt:
- input: Hier legen wir die orders.csv ab, welche unser Input Parameter ist
- output: Hier legt der Task die Results oder Errors ab
Nun können wir das Docker Image bauen und starten.
# Build Docker image
docker build -t auvery-task-clean-orders .
# Run docker image, mount volumes and set env variables
docker run --rm \
-e AUV_IN_CSV_FILE_PATH=/data/input/orders.csv \
-e AUV_OUT_JSON_FILE_PATH=/data/output/orders_clean.json \
-e AUV_ERR_CSV_ERROR=/data/output/csv_error.txt \
-e AUV_ERR_CLEANING_ERROR=/data/output/cleaning_error.txt \
-v $(pwd)/input:/data/input \
-v $(pwd)/output:/data/output \
auvery-task-clean-orders
Verwendung des Docker Images
Das oben beschriebene Docker Image ist öffentlich auf DockerHub verfügbar. Es kann unter dieser URL abgerufen werden hub.docker.com/r/auveryde/auvery-task-pandas-data-cleaning.
Um dieses Docker Image nun in auvery zu verwenden, müssen wir die Adresse der Registry sowie ein existierendes Tag in der Driver Configuration des Tasks hinterlegen. Dazu fügen wir die Registry URL im Feld Docker Image ein registry.hub.docker.com/auveryde/auvery-task-pandas-data-cleaning:latest.
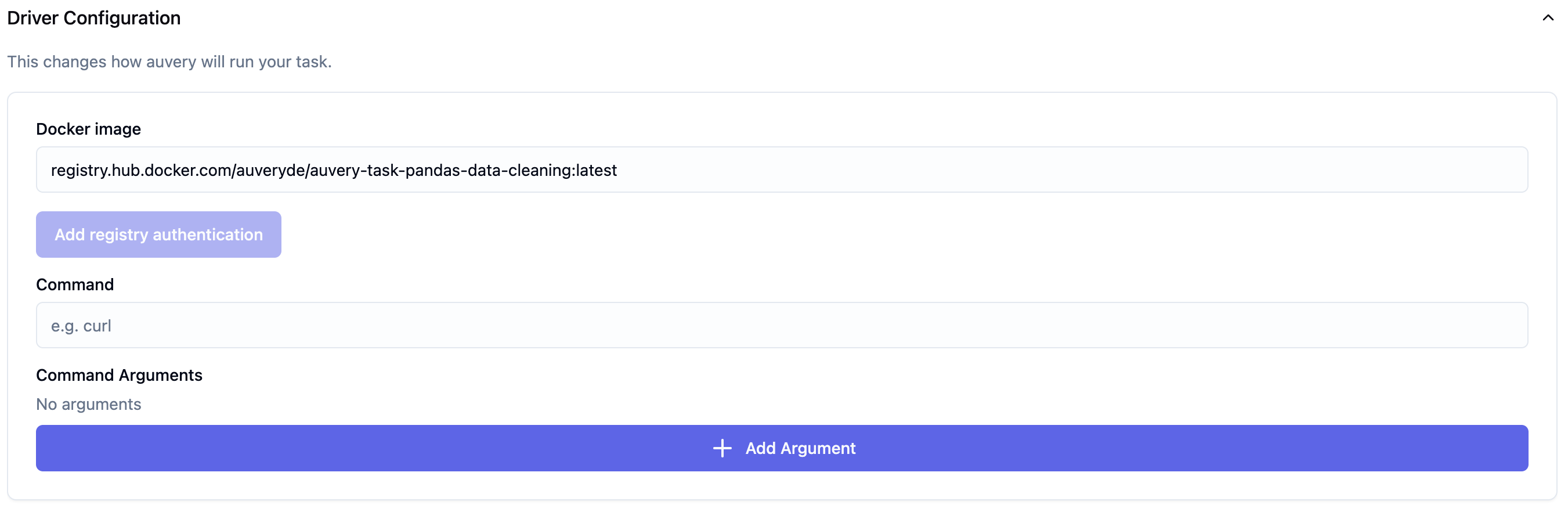
Anschließend kann der Task gespeichert und zu einem Workflow hinzugefügt werden. So können wir die Bereinigung von Daten als Teilschritt in einem als auvery Workflow automatisierten Geschäftsprozess nutzen.

